Les portes d’un train ne sont pas un équipement anodin. Elles constituent le premier point de contact entre le voyageur et le matériel, et leur défaillance a un impact immédiat sur l’exploitation : un train dont une porte ne se ferme pas correctement est immobilisé en gare. Sur un réseau à grande vitesse, chaque minute d’immobilisation se propage en cascade sur l’ensemble du plan de transport.
Nous avons accompagné un opérateur ferroviaire national dans la mise en place d’une surveillance prédictive de ses systèmes de portes, sur une flotte de trains à grande vitesse de nouvelle génération. Voici ce que cette expérience révèle sur les possibilités réelles de la maintenance prédictive appliquée au matériel roulant.
Le défi : des données massives, zéro historique de pannes
Le périmètre de départ était à la fois prometteur et intimidant. L’opérateur disposait de données embarquées issues des contrôleurs de portes (DCU) de sa flotte, enregistrant chaque cycle d’ouverture et de fermeture avec une résolution élevée. Sur une période de quelques semaines seulement, le jeu de données représentait près de 75 000 cycles analysés, soit plus de 10 millions d’enregistrements individuels.
Chaque cycle était décrit par plus de 129 variables : courant moteur, tension, vitesse de déplacement du vantail, positions, pressions, timestamps. Chaque cycle contenait entre 305 et 389 points de mesure. En termes de volume, les données ne manquaient pas.
En revanche, l’historique de pannes exploitable était quasi inexistant. Le matériel était récent, les défaillances rares, et quand elles survenaient, la correspondance entre l’événement de maintenance et les données capteurs n’était pas tracée dans les systèmes. Impossible d’entraîner un modèle supervisé classique. C’est précisément le type de situation où l’approche non supervisée, le « Mode Aveugle », prend tout son sens.
Des signaux bruts aux comportements : la méthode de clustering
La première étape n’a pas consisté à chercher des anomalies, mais à comprendre la variabilité normale du système. Car une porte de train ne se comporte pas de manière identique à chaque cycle. Les conditions d’exploitation changent : température extérieure, charge du train, paramètres électriques du réseau, usure des composants mécaniques.
L’analyse a procédé en trois temps. D’abord, un clustering indépendant sur chaque variable physique. Les formes d’ondes du courant moteur ont été regroupées par similarité, indépendamment de la tension et de la vitesse. De même pour les autres signaux. Chaque variable a révélé ses propres familles de comportement.
Ensuite, une agrégation globale a combiné les scores de clustering de chaque variable pour définir des « États Globaux » du système. Un cycle où le courant suit le profil de type 1, la tension le profil de type 1 et la vitesse le profil de type 1 est classé dans l’État A. Un cycle avec des profils différents tombe dans un autre état. Cette approche multi-variable permet de capturer des combinaisons de comportements que l’analyse d’une seule variable aurait manquées.
Enfin, les cycles atypiques, ceux qui ne correspondent à aucun cluster identifié, ont été isolés mathématiquement. Sur les 75 000 cycles, 4 cycles présentaient des durées anormales (supérieures à 1 minute, contre quelques secondes en fonctionnement normal). Ces outliers ont été séparés du jeu de données sain, confirmant la capacité de l’algorithme à discriminer le signal du bruit.
Quand les données révèlent l'invisible
Le résultat le plus frappant de cette phase d’analyse n’était pas la détection d’anomalies évidentes. C’était la mise en évidence de structures cachées dans les données que personne n’avait anticipées.
L’analyse temporelle a révélé que le système de portes alternait entre deux configurations de fonctionnement distinctes, avec des transitions nettes à des dates précises. Les profils de courant, de tension et de vitesse changeaient simultanément, suggérant un changement de paramétrage ou de mode de commande à l’échelle de la flotte. Cette découverte, invisible à l’œil nu dans les données brutes, avait une implication directe pour la suite du projet : construire un modèle prédictif sans distinguer ces deux configurations aurait généré des fausses alertes massives à chaque transition.
Par ailleurs, une régularité mécanique remarquable est apparue dans les séquences de cycles. Un cluster spécifique revenait à intervalles précis de 2 minutes et 49 secondes, quelle que soit la configuration active. Cette périodicité correspondait aux séquences d’essais automatiques du système, un comportement parfaitement normal mais que seule l’analyse algorithmique pouvait isoler dans le flux continu de données.
L’enseignement est clair : avant de déployer un modèle de détection d’anomalies, il faut d’abord comprendre la normalité dans toute sa complexité. Les données industrielles ne sont jamais simples, et les raccourcis méthodologiques se paient en fausses alertes.
Du diagnostic au prédictif : construire un modèle de surveillance
Cette première phase de caractérisation a posé les fondations du modèle prédictif. Les modes de fonctionnement nominaux étaient identifiés, la variabilité normale quantifiée, les cycles atypiques isolés. La « vérité terrain » était établie.
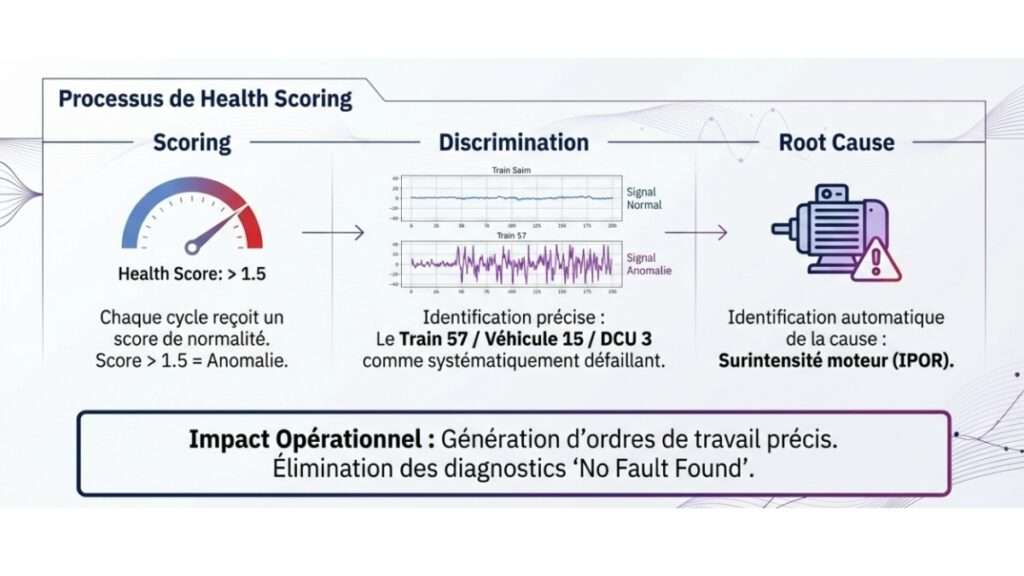
L’étape suivante consistait à alimenter le moteur de détection DiagFit en Mode Aveugle avec ces données de référence. Le modèle apprend la “Green Zone”, l’espace des comportements sains, puis calcule un score de santé (Health Indicator) pour chaque nouveau cycle de chaque porte de chaque véhicule.
Sur d’autres flottes où la même approche a été déployée à plus grande échelle, les résultats opérationnels sont probants. Le système de scoring permet de discriminer, au sein d’un parc de plusieurs centaines de trains, les équipements qui dérivent de ceux qui fonctionnent normalement. L’identification n’est pas générique : elle descend au niveau du train, du véhicule et du contrôleur de porte spécifique. Et l’analyse de root cause pointe automatiquement la variable responsable de la dégradation du score (surintensité moteur, dérive de tension, anomalie de vitesse).

L'impact opérationnel : en finir avec les interventions "à l'aveugle"
Pour les équipes de maintenance, le changement est tangible sur trois dimensions.
La précision du diagnostic transforme la nature des interventions. Au lieu de recevoir une alerte générique qui déclenche une inspection complète du système de portes, le technicien sait exactement quel organe examiner et quel type de défaut rechercher. Le temps de diagnostic sur le terrain est réduit, et les interventions « No Fault Found » (où le technicien ne trouve pas l’origine du problème) sont pratiquement éliminées.
La granularité du scoring permet une priorisation intelligente des interventions. Tous les scores supérieurs au seuil critique ne sont pas urgents de la même manière. Un équipement dont le score vient de franchir le seuil peut attendre la prochaine fenêtre de maintenance planifiée. Un équipement dont le score est en accélération depuis plusieurs jours nécessite une intervention rapide. Cette priorisation, impossible avec une simple alerte binaire, optimise l’allocation des ressources de maintenance.
Enfin, la visibilité sur la santé de l’ensemble du parc permet de passer d’une logique réactive (on intervient quand le conducteur signale un problème) à une logique proactive (on planifie l’intervention avant que le problème ne devienne visible en exploitation). C’est un changement de posture fondamental pour les directions de maintenance.





